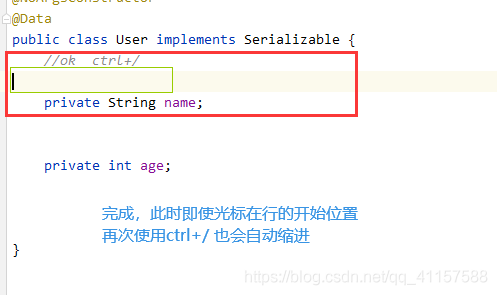
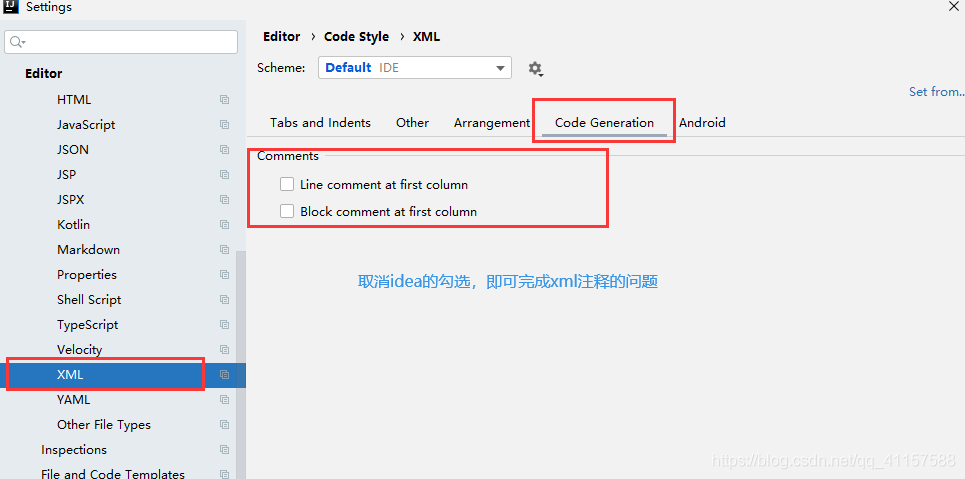
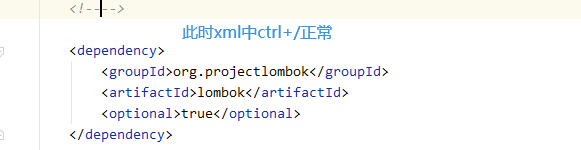
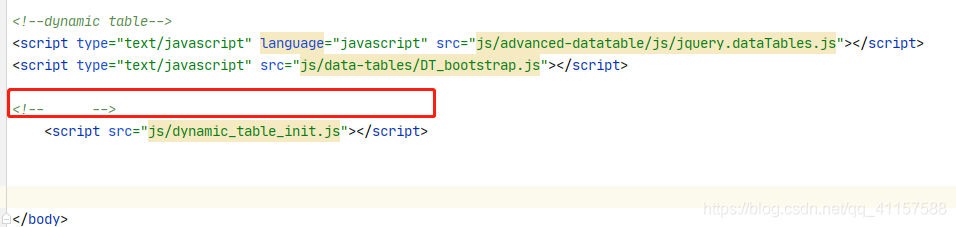
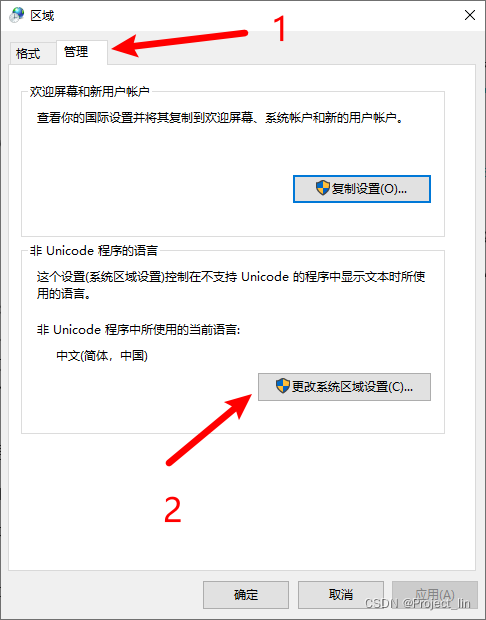
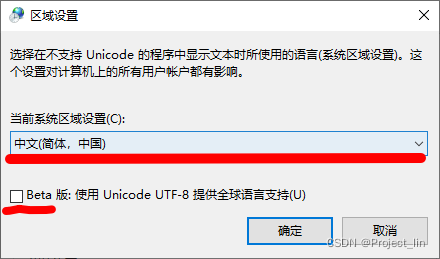
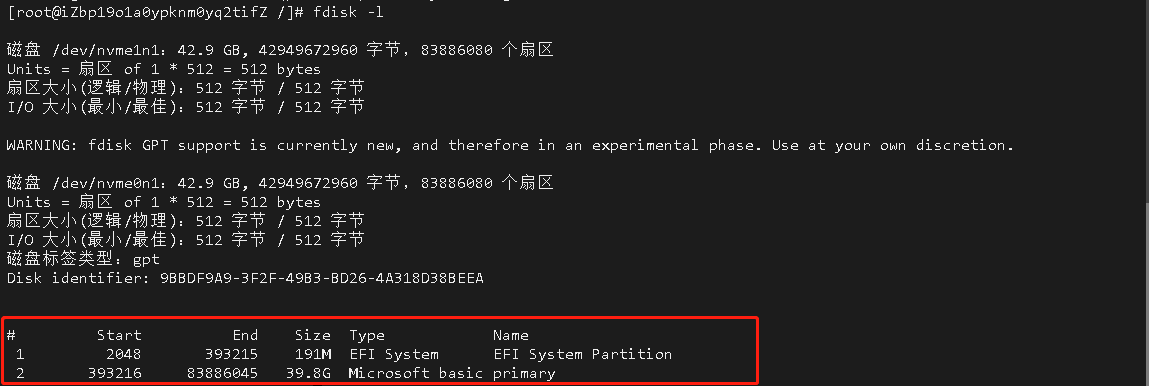
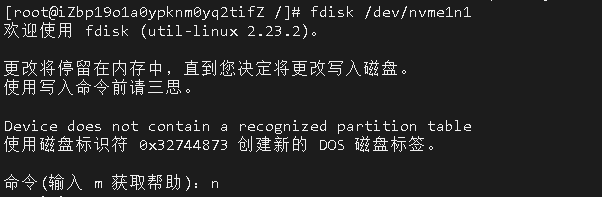
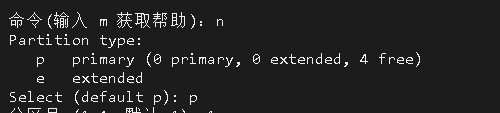
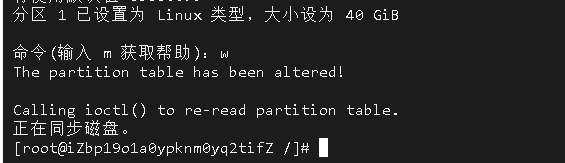
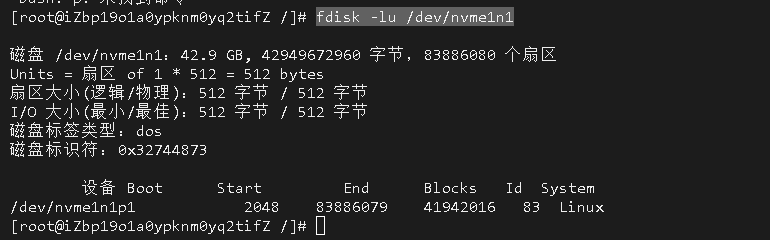
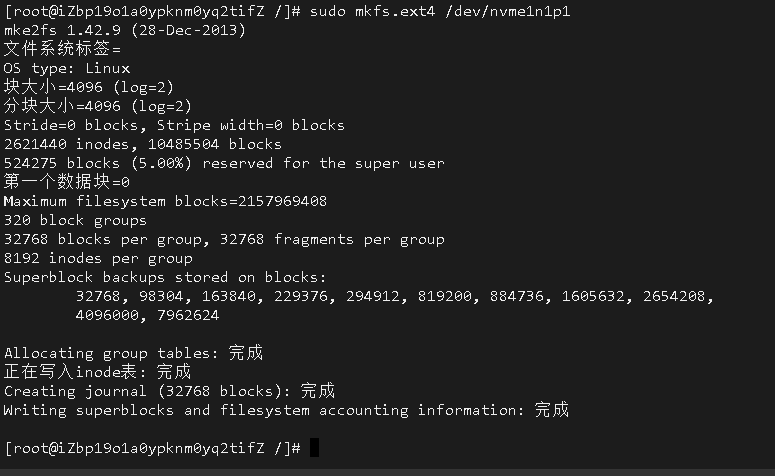
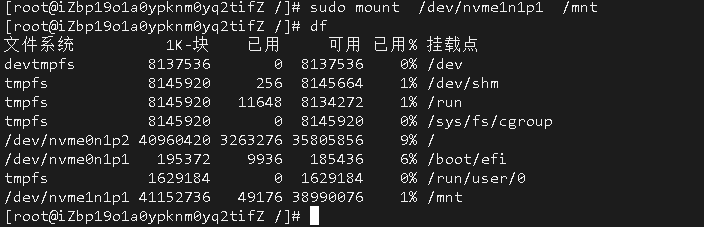
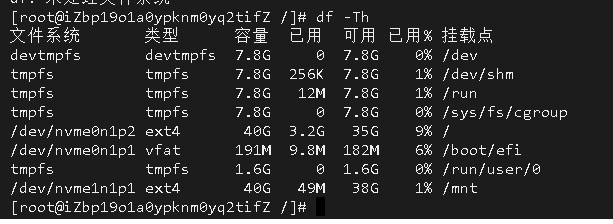
如果要使用异步加上 @EnableAsync 注解,方法上加 @Async 注解,如下 spring boot 项目配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
@SpringBootApplication @EnableAsync public class XApplication{ public static void main(String[] args) { ConfigurableApplicationContext run = new SpringApplicationBuilder(XApplication.class).web(true).run(args); run.publishEvent("test"); } }
@Async @EventListener public void test(String wrapped){ System.out.println("当前线程 "+Thread.currentThread().getName()); System.out.println(wrapped); }
@Override public void publishEvent(ApplicationEvent event) { publishEvent(event, null); }
protected void publishEvent(Object event, @Nullable ResolvableType eventType) { .............................. // Multicast right now if possible - or lazily once the multicaster is initialized if (this.earlyApplicationEvents != null) { this.earlyApplicationEvents.add(applicationEvent); } else { // 进入multicastEvent getApplicationEventMulticaster().multicastEvent(applicationEvent, eventType); }
// Publish event via parent context as well... if (this.parent != null) { if (this.parent instanceof AbstractApplicationContext) { ((AbstractApplicationContext) this.parent).publishEvent(event, eventType); } else { this.parent.publishEvent(event); } } }
private void doInvokeListener(ApplicationListener listener, ApplicationEvent event) { try { listener.onApplicationEvent(event); } catch (ClassCastException ex) { String msg = ex.getMessage(); if (msg == null || matchesClassCastMessage(msg, event.getClass().getName())) { // Possibly a lambda-defined listener which we could not resolve the generic event type for // -> let's suppress the exception and just log a debug message. Log logger = LogFactory.getLog(getClass()); if (logger.isDebugEnabled()) { logger.debug("Non-matching event type for listener: " + listener, ex); } } else { throw ex; } } }
@Override public void onApplicationEvent(ApplicationEvent event) { processEvent(event); } ApplicationListenerMethodAdapter#processEvent public void processEvent(ApplicationEvent event) { Object[] args = resolveArguments(event); if (shouldHandle(event, args)) { // 执行真正的方法 Object result = doInvoke(args); if (result != null) { handleResult(result); } else { logger.trace("No result object given - no result to handle"); } } }
protected Object getTargetBean() { Assert.notNull(this.applicationContext, "ApplicationContext must no be null"); return this.applicationContext.getBean(this.beanName); }
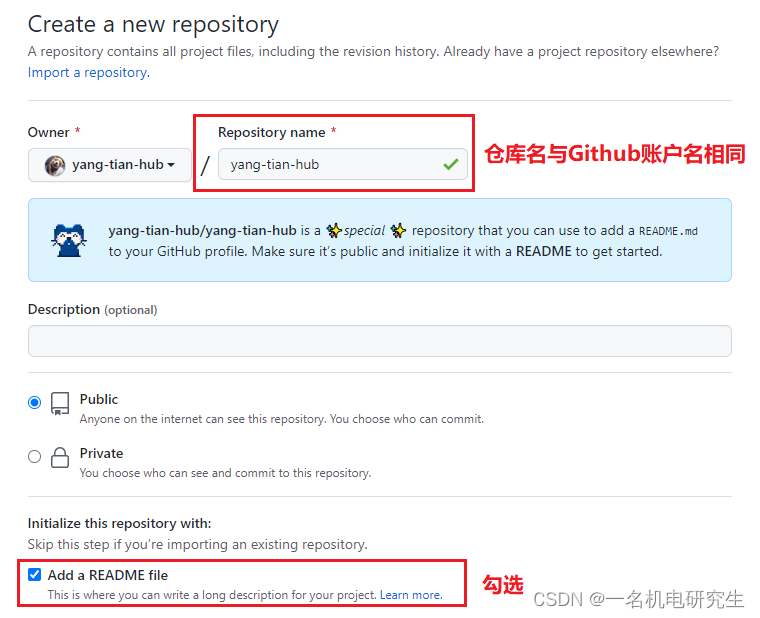
xxxx/xxxx is a ✨special ✨ repository that you can use to add a README.md to your GitHub profile. Make sure it’s public and initialize it with a README to get started.
publicstatic NotifyType of(String messageType) { for (NotifyType notifyType : typeMap.keySet()) { if (typeMap.get(notifyType).equals(messageType)) { return notifyType; } } thrownewIllegalArgumentException("No such enum object for the given messageType"); }
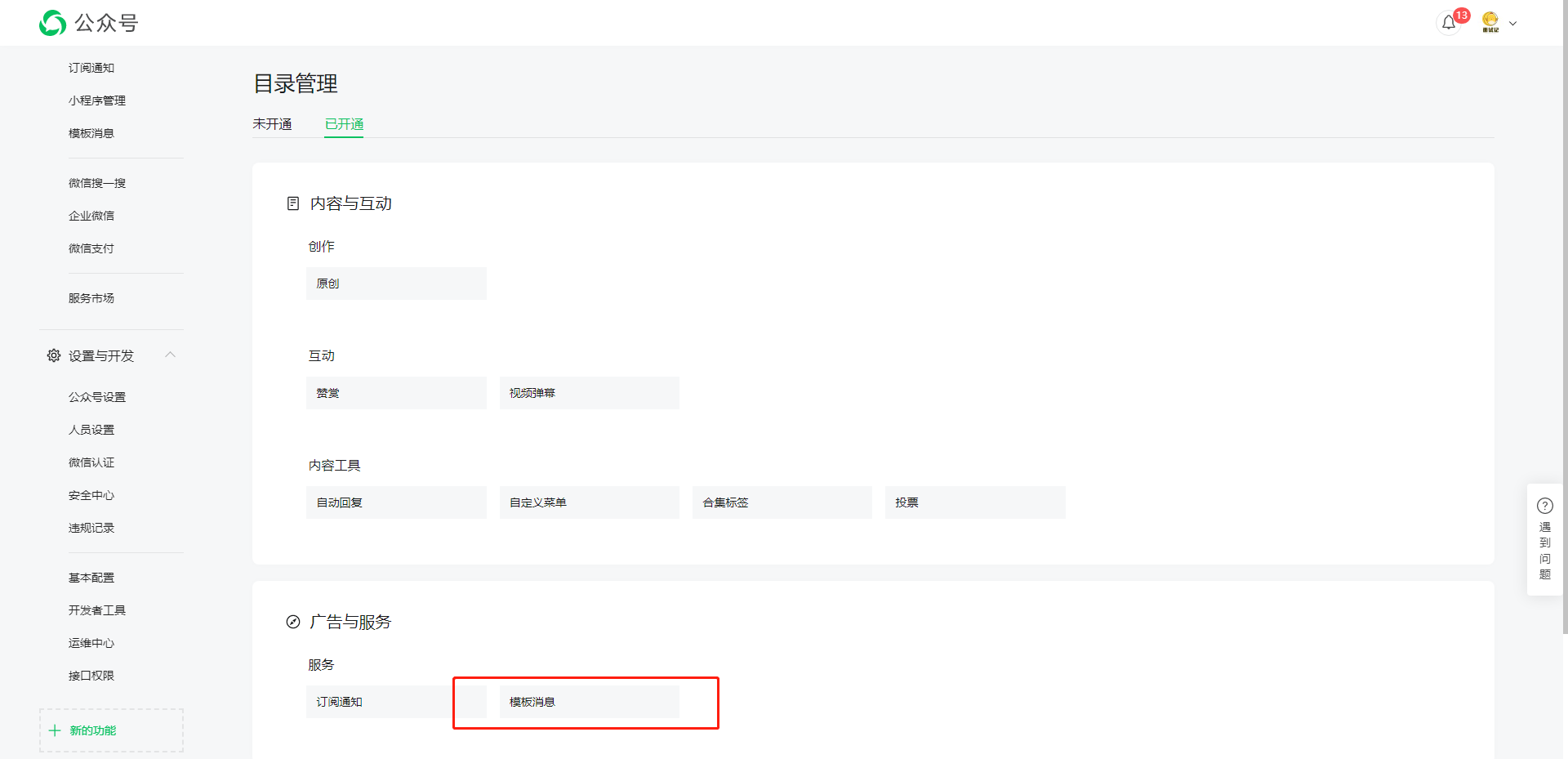
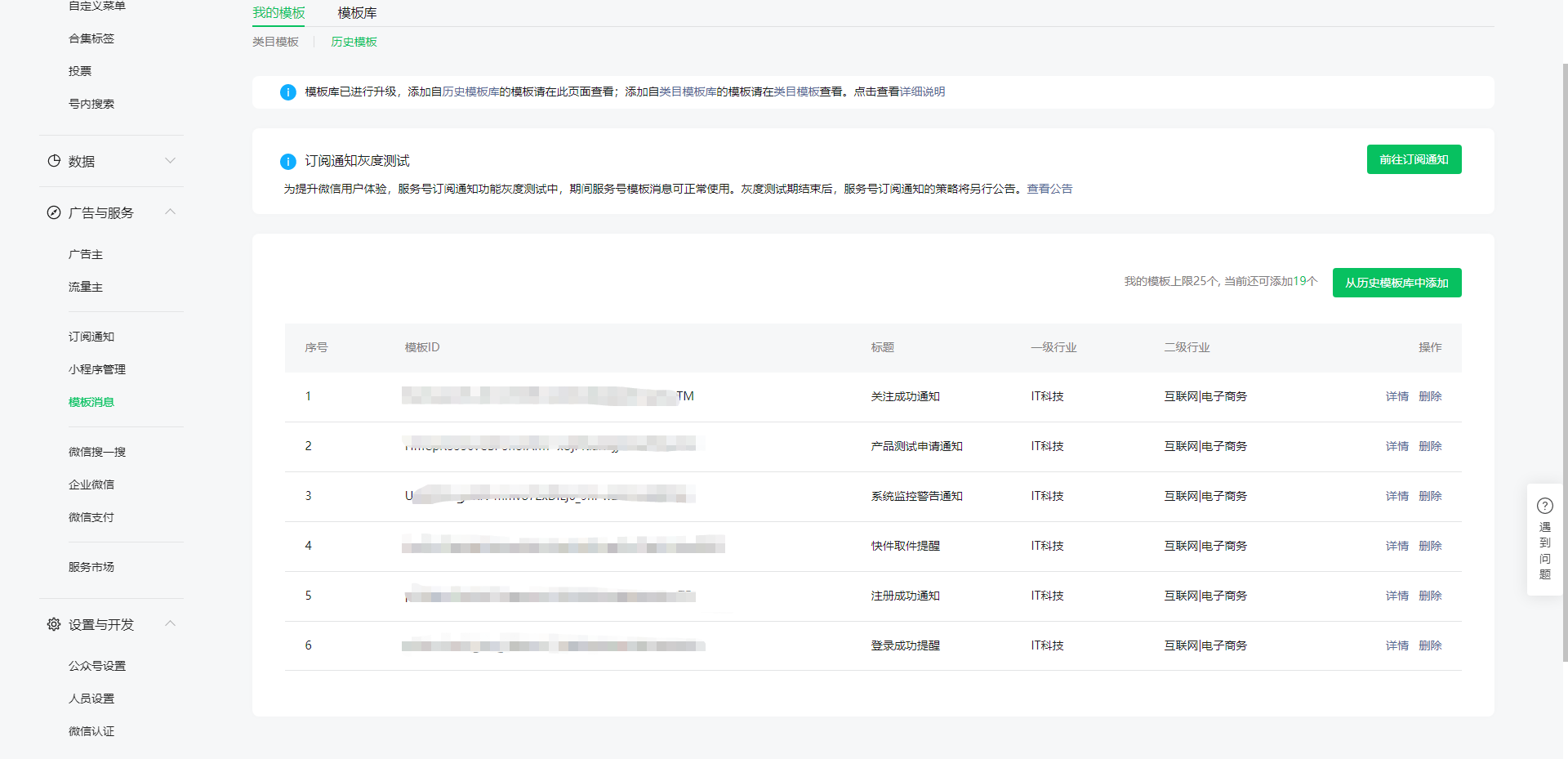
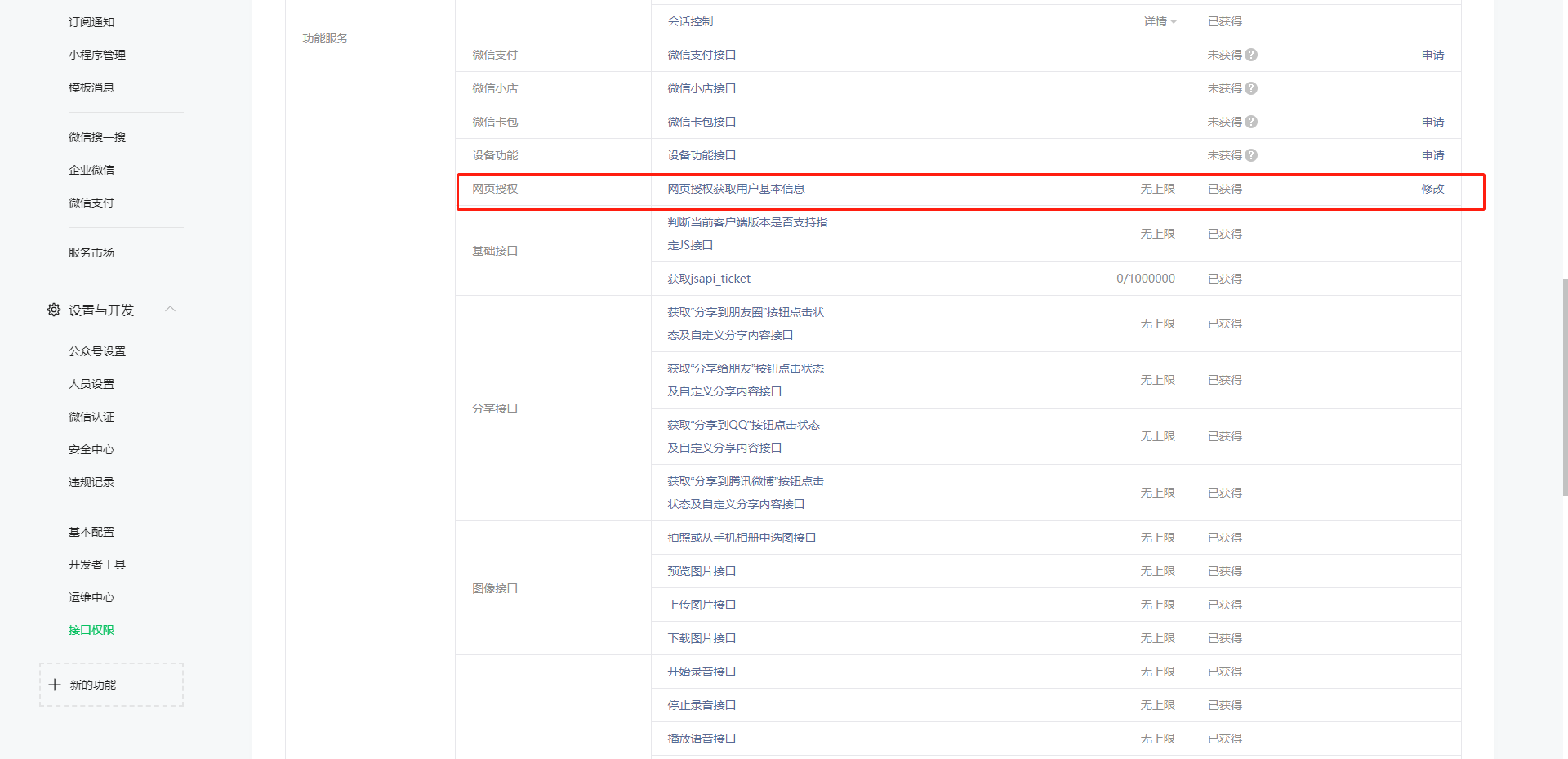
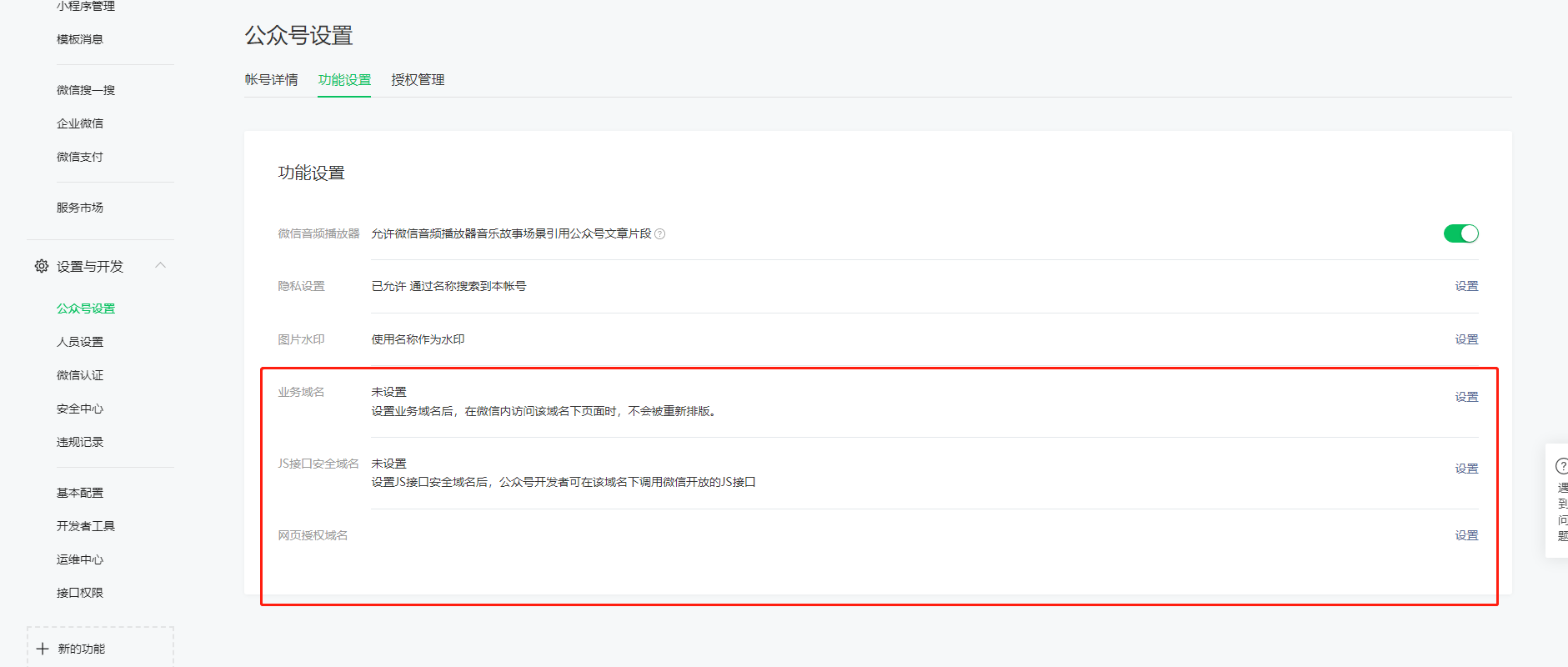
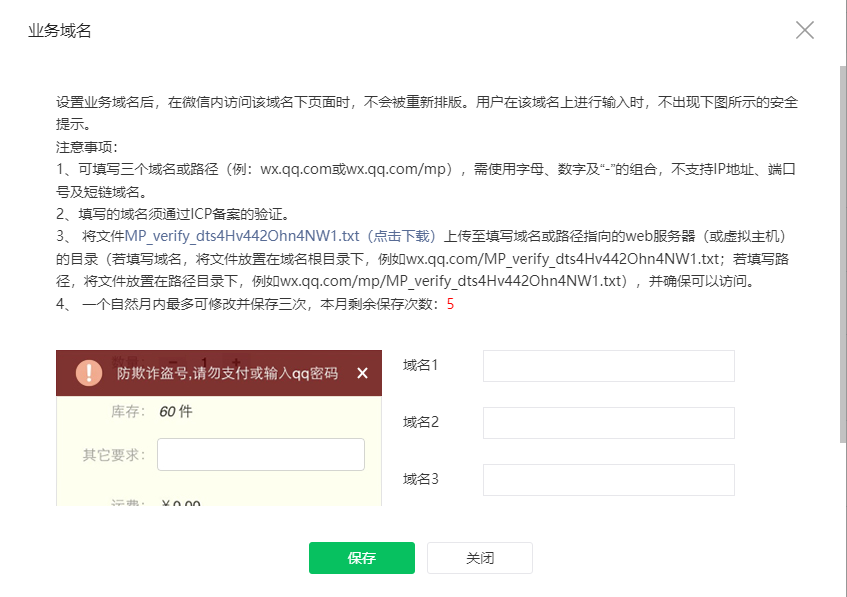
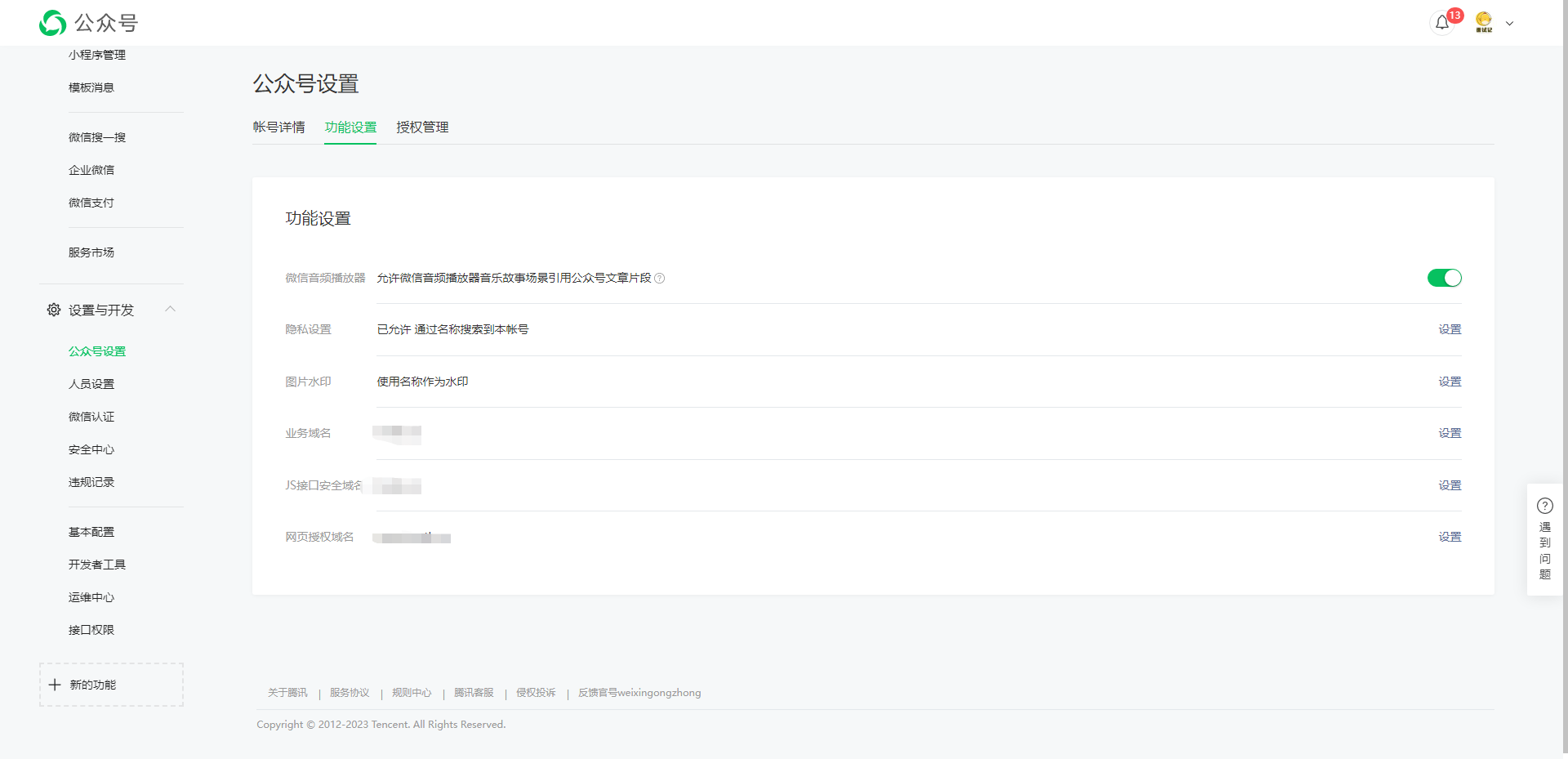
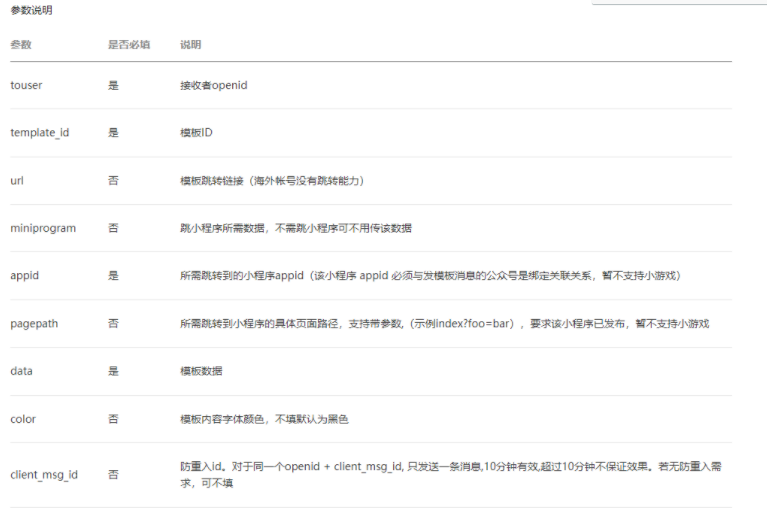
后续获取 access_token 访问接口时,需要设置访问来源 IP 为白名单,如不配置就拿不到 token,每台机器上请求返回的 ip 都会不一样,把开发机器和服务器拿到的 ip 都配置一样就好,配置多个 ip 时每个 ip 用回车隔开就行。怎么获取来源 ip:如果没有配置 ip 白名单,请求获取 access_token 时会返回一个 ip,把这个 ip 配上去就行了。另外顺便保存一下 appId 和 AppSecret,方便后续使用。
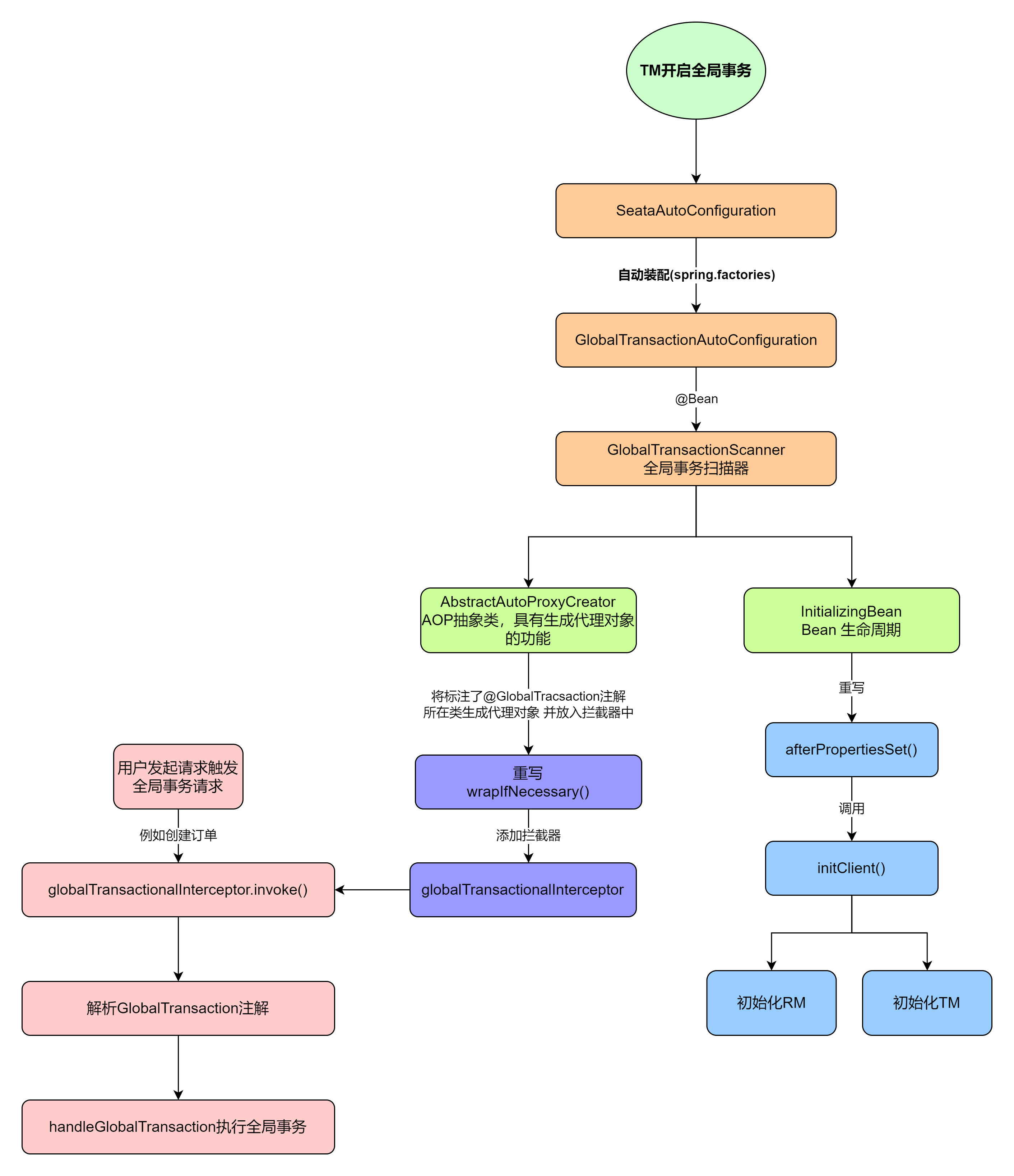
privatevoidinitClient() { //启动日志 if (LOGGER.isInfoEnabled()) { LOGGER.info("Initializing Global Transaction Clients ... "); } //检查应用名以及事务分组名,为空抛出异常IllegalArgumentException if (DEFAULT_TX_GROUP_OLD.equals(txServiceGroup)) { LOGGER.warn("the default value of seata.tx-service-group: {} has already changed to {} since Seata 1.5, " + "please change your default configuration as soon as possible " + "and we don't recommend you to use default tx-service-group's value provided by seata", DEFAULT_TX_GROUP_OLD, DEFAULT_TX_GROUP); } if (StringUtils.isNullOrEmpty(applicationId) || StringUtils.isNullOrEmpty(txServiceGroup)) { thrownewIllegalArgumentException(String.format("applicationId: %s, txServiceGroup: %s", applicationId, txServiceGroup)); } //init TM //初始化TM TMClient.init(applicationId, txServiceGroup, accessKey, secretKey); if (LOGGER.isInfoEnabled()) { LOGGER.info("Transaction Manager Client is initialized. applicationId[{}] txServiceGroup[{}]", applicationId, txServiceGroup); } //init RM //初始化RM RMClient.init(applicationId, txServiceGroup); if (LOGGER.isInfoEnabled()) { LOGGER.info("Resource Manager is initialized. applicationId[{}] txServiceGroup[{}]", applicationId, txServiceGroup); }
if (LOGGER.isInfoEnabled()) { LOGGER.info("Global Transaction Clients are initialized. "); } registerSpringShutdownHook();
}
@Override publicvoidafterPropertiesSet() { if (disableGlobalTransaction) { if (LOGGER.isInfoEnabled()) { LOGGER.info("Global transaction is disabled."); } ConfigurationCache.addConfigListener(ConfigurationKeys.DISABLE_GLOBAL_TRANSACTION, (ConfigurationChangeListener)this); return; } if (initialized.compareAndSet(false, true)) { initClient(); } } privatevoidinitClient() { //启动日志 if (LOGGER.isInfoEnabled()) { LOGGER.info("Initializing Global Transaction Clients ... "); } //检查应用名以及事务分组名,为空抛出异常IllegalArgumentException if (DEFAULT_TX_GROUP_OLD.equals(txServiceGroup)) { LOGGER.warn("the default value of seata.tx-service-group: {} has already changed to {} since Seata 1.5, " + "please change your default configuration as soon as possible " + "and we don't recommend you to use default tx-service-group's value provided by seata", DEFAULT_TX_GROUP_OLD, DEFAULT_TX_GROUP); }
//检查应用名以及事务分组名,为空抛出异常IllegalArgumentException if (StringUtils.isNullOrEmpty(applicationId) || StringUtils.isNullOrEmpty(txServiceGroup)) { thrownewIllegalArgumentException(String.format("applicationId: %s, txServiceGroup: %s", applicationId, txServiceGroup)); } //init TM //初始化TM TMClient.init(applicationId, txServiceGroup, accessKey, secretKey); if (LOGGER.isInfoEnabled()) { LOGGER.info("Transaction Manager Client is initialized. applicationId[{}] txServiceGroup[{}]", applicationId, txServiceGroup); } //init RM //初始化RM RMClient.init(applicationId, txServiceGroup); if (LOGGER.isInfoEnabled()) { LOGGER.info("Resource Manager is initialized. applicationId[{}] txServiceGroup[{}]", applicationId, txServiceGroup); }
if (LOGGER.isInfoEnabled()) { LOGGER.info("Global Transaction Clients are initialized. "); } registerSpringShutdownHook();
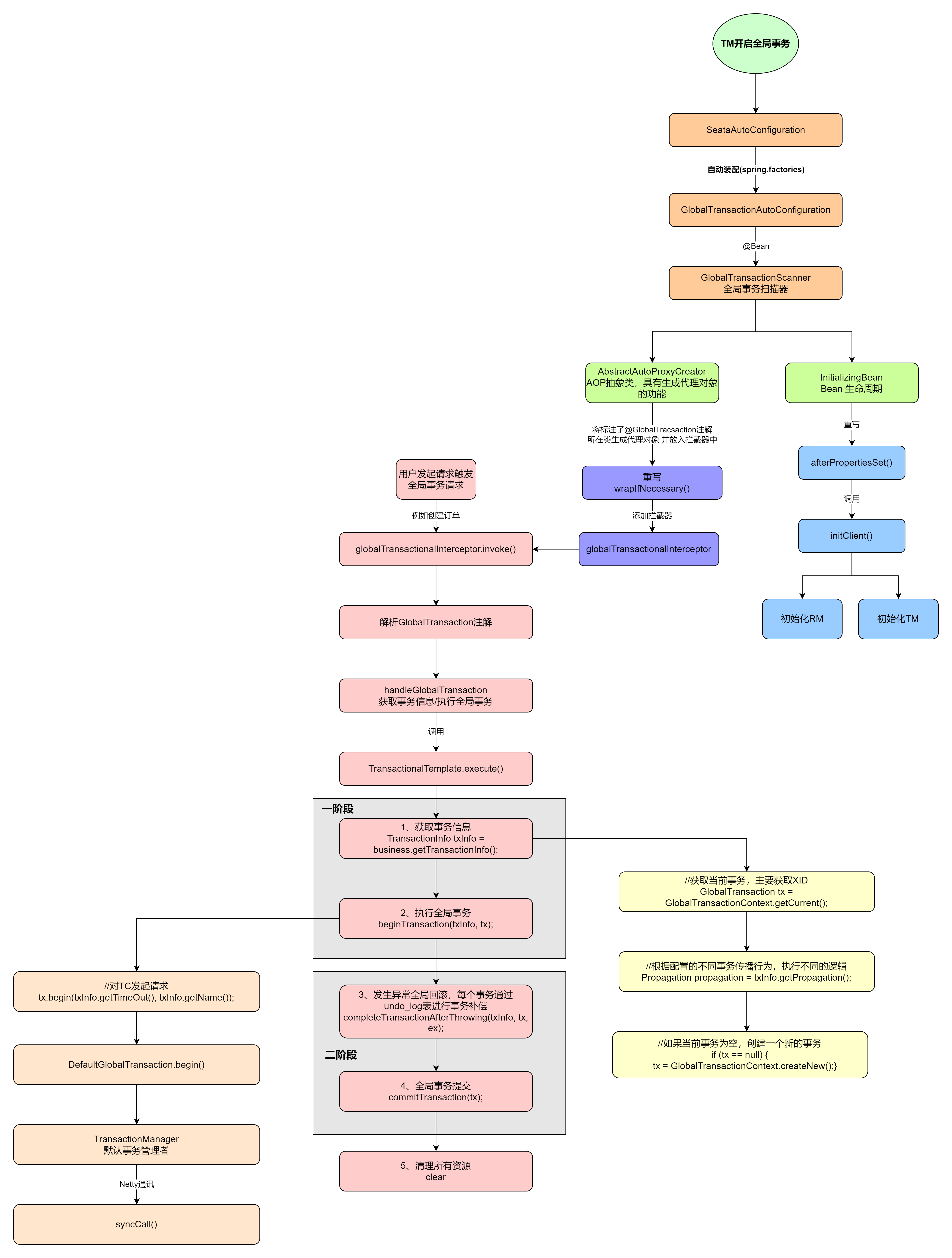
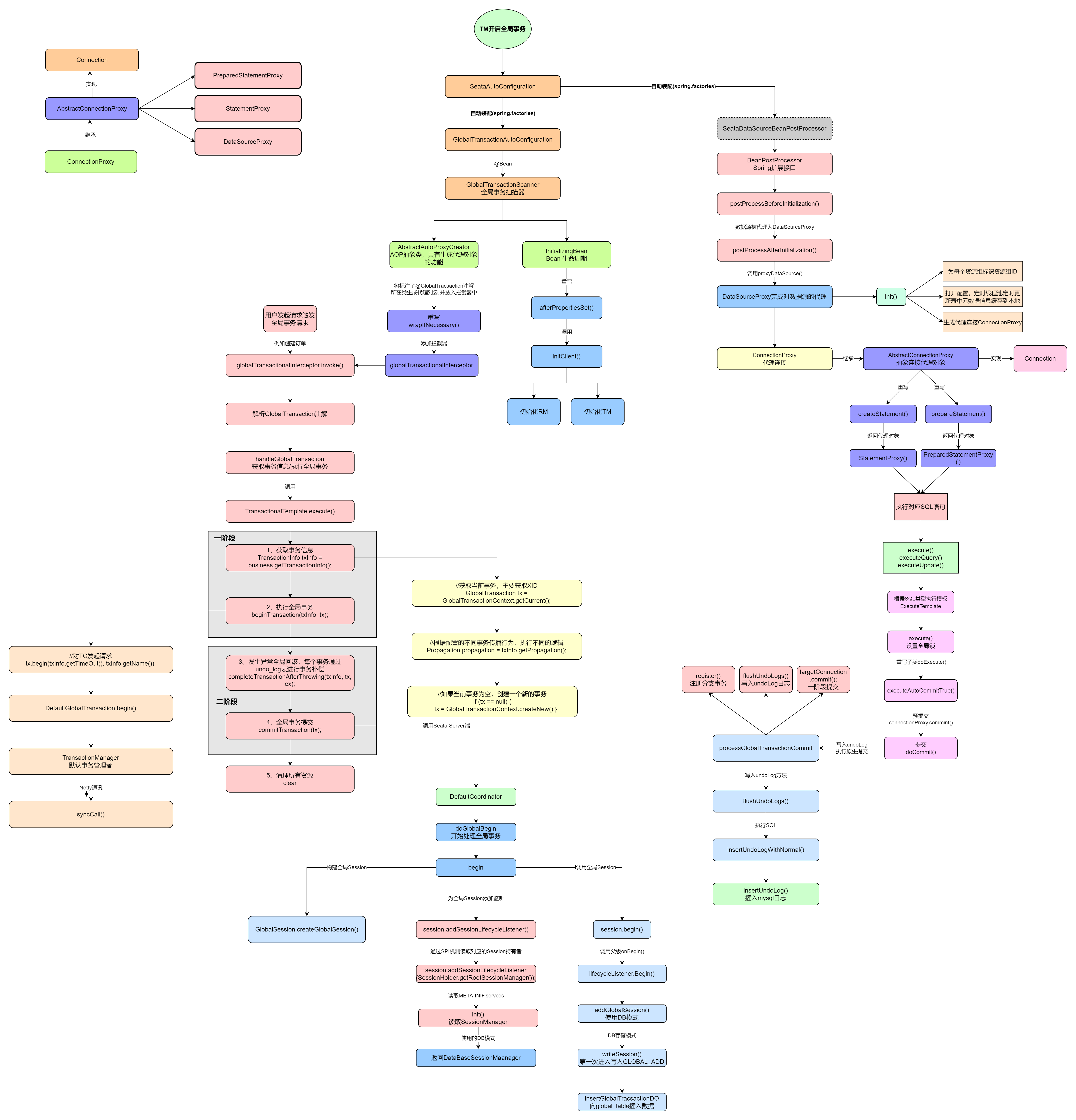
public Object execute(TransactionalExecutor business)throws Throwable { // 1. Get transactionInfo //获取事务信息 TransactionInfotxInfo= business.getTransactionInfo(); if (txInfo == null) { thrownewShouldNeverHappenException("transactionInfo does not exist"); } // 1.1 Get current transaction, if not null, the tx role is 'GlobalTransactionRole.Participant'. //获取当前事务,主要获取XID GlobalTransactiontx= GlobalTransactionContext.getCurrent();
// 1.2 Handle the transaction propagation. //根据配置的不同事务传播行为,执行不同的逻辑 Propagationpropagation= txInfo.getPropagation(); SuspendedResourcesHoldersuspendedResourcesHolder=null; try { switch (propagation) { case NOT_SUPPORTED: // If transaction is existing, suspend it. if (existingTransaction(tx)) { suspendedResourcesHolder = tx.suspend(); } // Execute without transaction and return. return business.execute(); case REQUIRES_NEW: // If transaction is existing, suspend it, and then begin new transaction. if (existingTransaction(tx)) { suspendedResourcesHolder = tx.suspend(); tx = GlobalTransactionContext.createNew(); } // Continue and execute with new transaction break; case SUPPORTS: // If transaction is not existing, execute without transaction. if (notExistingTransaction(tx)) { return business.execute(); } // Continue and execute with new transaction break; case REQUIRED: // If current transaction is existing, execute with current transaction, // else continue and execute with new transaction. break; case NEVER: // If transaction is existing, throw exception. if (existingTransaction(tx)) { thrownewTransactionException( String.format("Existing transaction found for transaction marked with propagation 'never', xid = %s" , tx.getXid())); } else { // Execute without transaction and return. return business.execute(); } case MANDATORY: // If transaction is not existing, throw exception. if (notExistingTransaction(tx)) { thrownewTransactionException("No existing transaction found for transaction marked with propagation 'mandatory'"); } // Continue and execute with current transaction. break; default: thrownewTransactionException("Not Supported Propagation:" + propagation); }
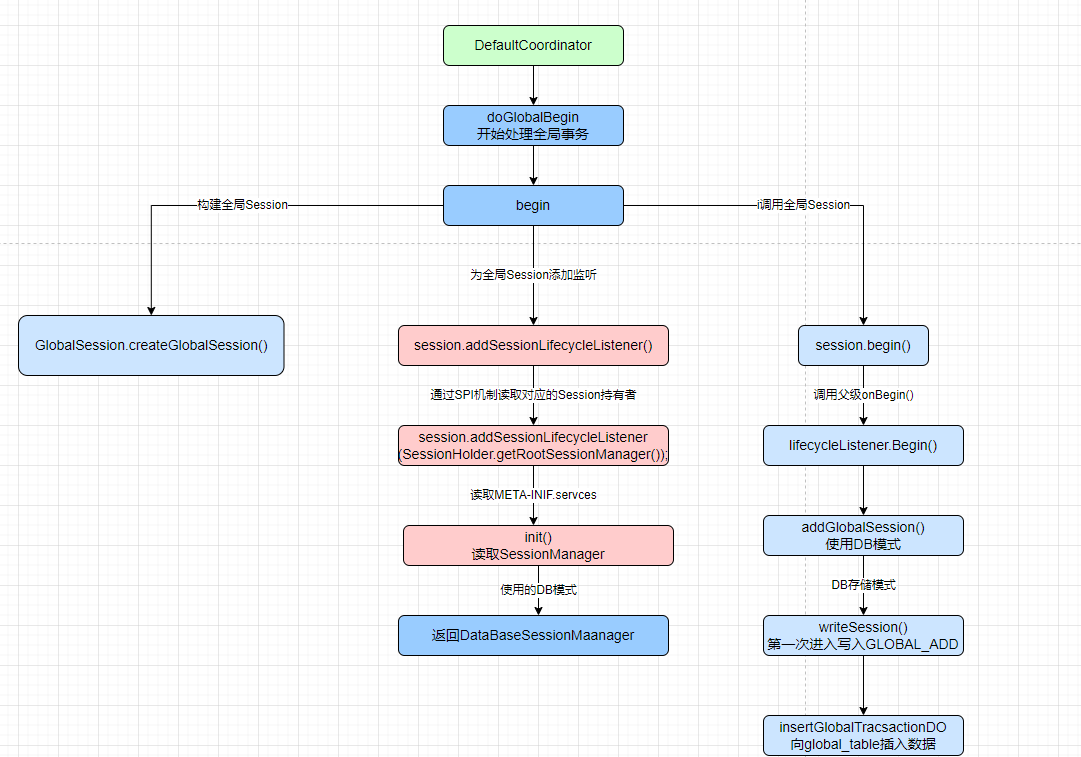
// 1.3 If null, create new transaction with role 'GlobalTransactionRole.Launcher'. //如果当前事务为空,创建一个新的事务 if (tx == null) { tx = GlobalTransactionContext.createNew(); }
// set current tx config to holder GlobalLockConfigpreviousConfig= replaceGlobalLockConfig(txInfo);
try { // 2. If the tx role is 'GlobalTransactionRole.Launcher', send the request of beginTransaction to TC, // else do nothing. Of course, the hooks will still be triggered. //开始执行全局事务 beginTransaction(txInfo, tx);
Object rs; try { // Do Your Business // 执行当前业务逻辑 //1、在TC注册当前分支事务,TC会在branch_table中插入一条分支事务数据 //2、执行本地update语句,并在执行前后查询数据状态,并把数据前后镜像存入到undo_log中 //3、远程调用其他应用,远程应用接收到XID,也会注册分支事务,写入branch_table以及本地undo_log表 //4、会在lock_table表中插入全局锁数据(一个分支一条) rs = business.execute(); } catch (Throwable ex) { // 3. The needed business exception to rollback. //发生异常全局回滚,每个事务通过undo_log表进行事务补偿 completeTransactionAfterThrowing(txInfo, tx, ex); throw ex; }
// 4. everything is fine, commit. //全局提交 commitTransaction(tx);
return rs; } finally { //5. clear //清理所有资源 resumeGlobalLockConfig(previousConfig); triggerAfterCompletion(); cleanUp(); } } finally { // If the transaction is suspended, resume it. if (suspendedResourcesHolder != null) { tx.resume(suspendedResourcesHolder); } } }
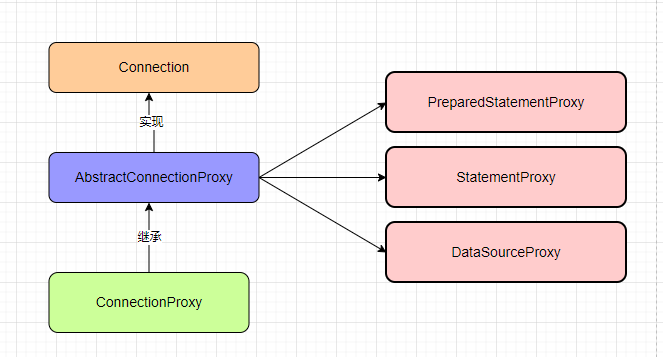
publicstatic <T, S extendsStatement> T execute(List<SQLRecognizer> sqlRecognizers, StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback, Object... args)throws SQLException { //如果没有全局锁,并且不是AT模式,直接执行SQL if (!RootContext.requireGlobalLock() && BranchType.AT != RootContext.getBranchType()) { // Just work as original statement return statementCallback.execute(statementProxy.getTargetStatement(), args); }
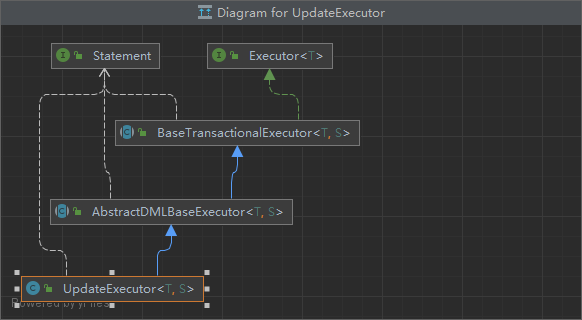
//得到数据库类型- mysql/oracle StringdbType= statementProxy.getConnectionProxy().getDbType(); if (CollectionUtils.isEmpty(sqlRecognizers)) { //sqlRecognizers 为SQL语句的解析器,获取执行的SQL,通过它可以获得SQL语句表名、相关的列名、类型等信息,最后解析出对应的SQL表达式 sqlRecognizers = SQLVisitorFactory.get( statementProxy.getTargetSQL(), dbType); } Executor<T> executor; if (CollectionUtils.isEmpty(sqlRecognizers)) { //如果seata没有找到合适的SQL语句解析器,那么便创建简单执行器PlainExecutor //PlainExecutor直接使用原生的Statment对象执行SQL executor = newPlainExecutor<>(statementProxy, statementCallback); } else { if (sqlRecognizers.size() == 1) { SQLRecognizersqlRecognizer= sqlRecognizers.get(0); switch (sqlRecognizer.getSQLType()) { //新增 case INSERT: executor = EnhancedServiceLoader.load(InsertExecutor.class, dbType, newClass[]{StatementProxy.class, StatementCallback.class, SQLRecognizer.class}, newObject[]{statementProxy, statementCallback, sqlRecognizer}); break; //修改 case UPDATE: executor = newUpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer); break; //删除 case DELETE: executor = newDeleteExecutor<>(statementProxy, statementCallback, sqlRecognizer); break; //加锁 case SELECT_FOR_UPDATE: executor = newSelectForUpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer); break; //插入加锁 case INSERT_ON_DUPLICATE_UPDATE: switch (dbType) { case JdbcConstants.MYSQL: case JdbcConstants.MARIADB: executor = newMySQLInsertOrUpdateExecutor(statementProxy, statementCallback, sqlRecognizer); break; default: thrownewNotSupportYetException(dbType + " not support to INSERT_ON_DUPLICATE_UPDATE"); } break; //原生 default: executor = newPlainExecutor<>(statementProxy, statementCallback); break; } } else { //批量处理SQL语句 executor = newMultiExecutor<>(statementProxy, statementCallback, sqlRecognizers); } } T rs; try { //执行 rs = executor.execute(args); } catch (Throwable ex) { if (!(ex instanceof SQLException)) { // Turn other exception into SQLException ex = newSQLException(ex); } throw (SQLException) ex; } return rs; }
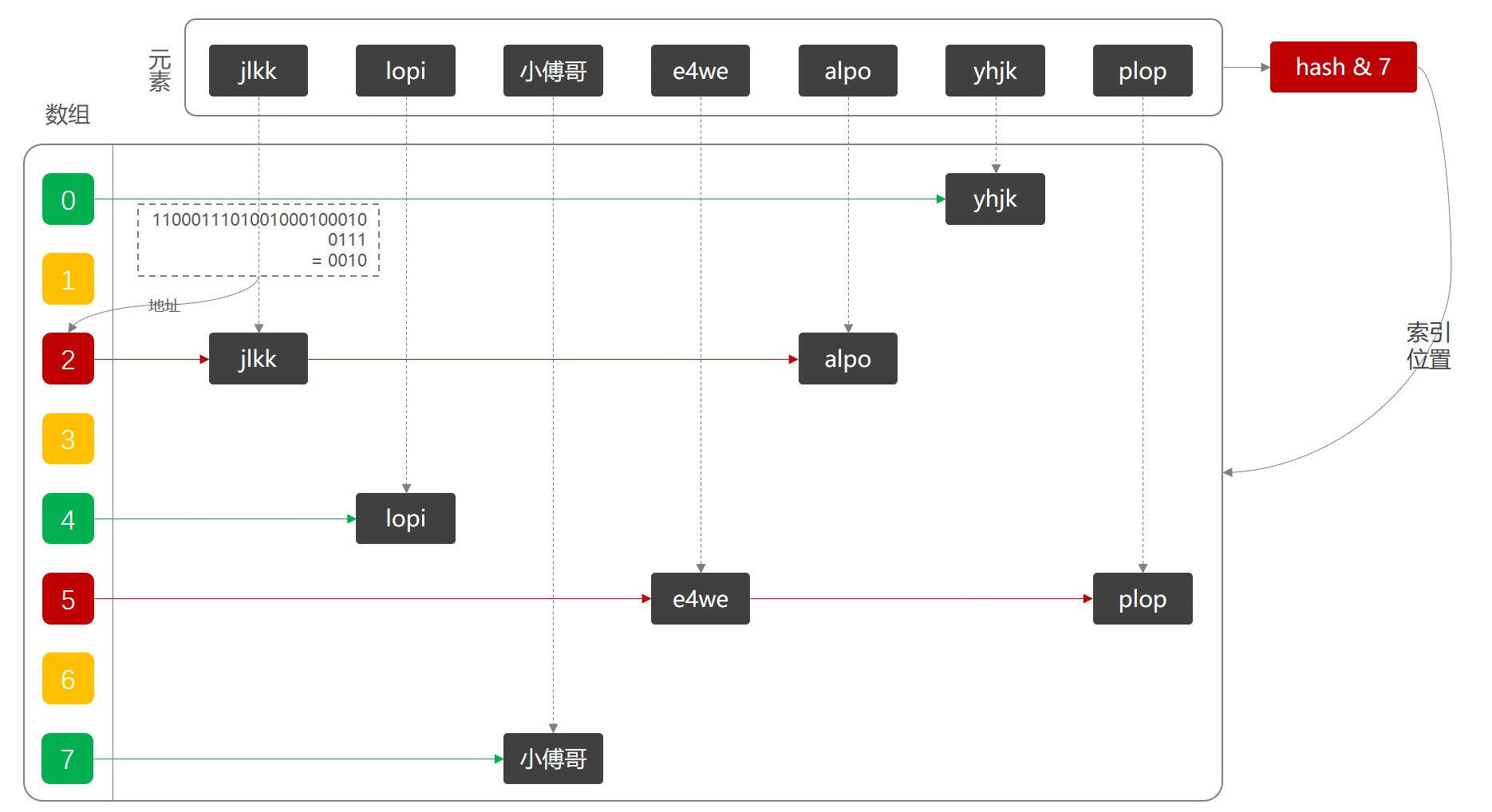
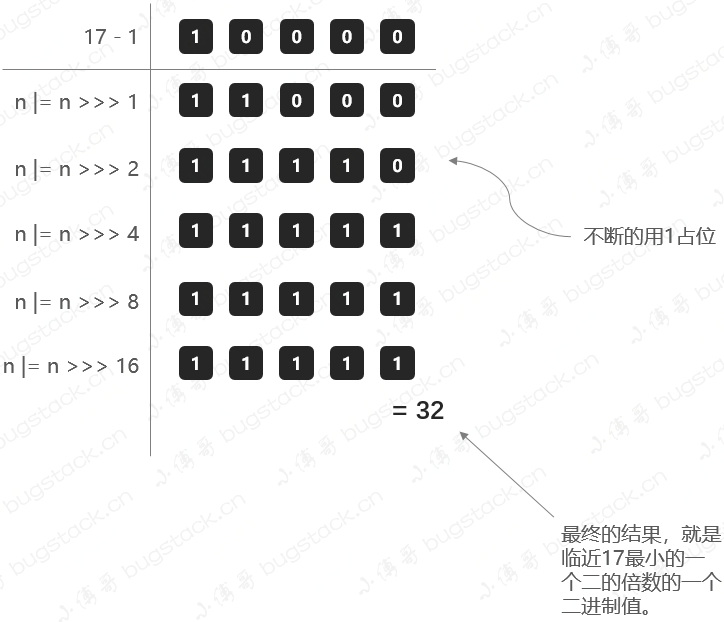
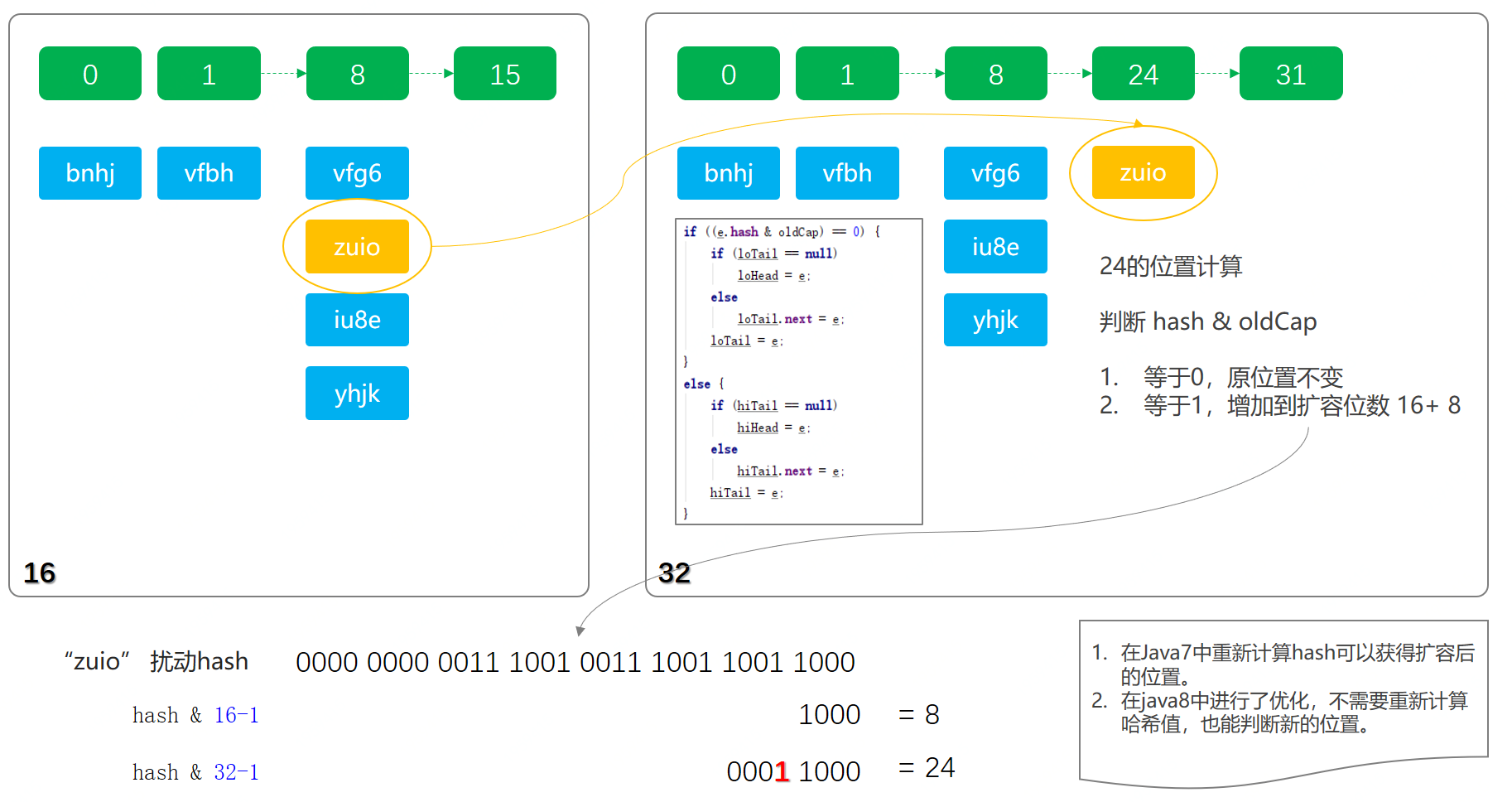
staticfinalinttableSizeFor(int cap) { intn= cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }